
En la búsqueda del código más óptimo* nos solemos encontrar a menudo con varios problemas. ¿Qué se quiere mejorar? ¿El tiempo de ejecución? ¿La limpieza de código? ¿Usar espacios o tabulaciones en el sangrado (identation) del código? ¿El nivel de acoplamiento de nuestros objetos? ¿El uso de buenas prácticas?
En este artículo nos centraremos en el rendimiento, que ha sido uno de los pilares en el desarrollo de muchos de nuestros servicios y, cómo el correcto uso de la estructura HashSet<T> que ofrece .NET, nos ha permitido reducir drásticamente los tiempos de ejecución de algunos métodos críticos.
Pero antes, un breve apunte matemático: se llama conjunto a toda agrupación, colección o reunión de individuos (cosas, animales, personas o números) cuyos elementos no se repiten, es decir, son únicos. En otras palabras, el conjunto {2, 3, 5} es idéntico al conjunto {3, 5, 2}, mientras que el conjunto {3, 5, 5, 2} sería inválido debido a tener un elemento duplicado (el 5). Asimismo, existe una serie de operaciones básicas con conjuntos que pertenecen a la denominada álgebra de conjuntos que son:
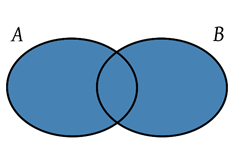
- Unión: La unión de dos conjuntos A y B es el conjunto formado por todos los elementos comunes y no comunes de ambos conjuntos.
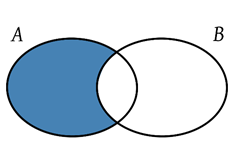
- Diferencia: La diferencia entre de dos conjuntos A y B es el conjunto formado por todos los elementos no comunes del conjunto B respecto al conjunto A; es decir, los elementos que están en A, pero no están en B.
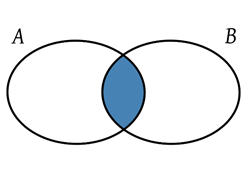
- Intersección: La intersección de dos conjuntos A y B es el conjunto formado por todos los elementos comunes de ambos conjuntos (sin repetir elementos).
¿Qué tiene que ver todo esto con el rendimiento de nuestro código? El framework .NET nos ofrece dos implementaciones basadas en estructuras de conjuntos (sets): el HashSet<T> y el SortedSet<T>. ¿Y, por qué deberíamos considerar usar estas estructuras en vez de usar otras implementaciones de colecciones, tales como, listas? Principalmente, porque los sets son extremadamente eficientes para realizar operaciones de búsqueda o filtrado.
La principal diferencia entre HashSet<T> y SortedSet<T> consiste en que el este último guarda sus elementos de forma ordenada, lo que se traduce en un rendimiento menor para operaciones de inserción y borrado (serían de O(n) frente a O(1)), pero que puede llegar a ser útil para aquellas situaciones en las que debemos realizar una ordenación después de hacer una operación con el conjunto. En cualquier caso, si no vamos a aprovechar la ordenación de los elementos, el coste de SortedSet<T> es demasiado alto y HashSet<T> sería más adecuado.
Pongamos, por ejemplo, que tenemos una lista de elementos, y queremos filtrarla antes de mostrarla. Para ello, como parámetro de entrada tendremos por un lado los elementos a filtrar – elements – y los elementos que constituyen el filtro – allowedElements.
En este ejemplo, el proceso de filtrado no es más que la intersección de ambos conjuntos de elementos:
public List<int> Filter(List<int> allowedElements, List<int> elements)
{
var filteredElements = new List<int>();
foreach (var mElement in elements)
{
if (allowedElements.Contains(mElement))
filteredElements.Add(mElement);
}
return filteredElements;
}
¿Qué está mal en este código? En principio, es un código que funciona y es fácil de entender, pero el rendimiento podría ser mejor: buscar un elemento con Contains en una List<T> es una operación de coste lineal - O(n) -. En el peor de los casos, el objeto a buscar en la lista allowedElements estaría en último lugar, lo que supondría tener que recorrer toda la lista de allowedElements para encontrarlo. Es más, el Contains se ejecuta dentro del bucle que recorre la lista de elements, lo que supone que el método tendrá un coste mayor - O(n*m) - que se incrementará en función del número de elements (la m en la anterior multiplicación) y del número de elementos permitidos que hay en la lista allowedElements.
Utilizar un HashSet<T> puede solucionarnos problemas como el ejemplo propuesto de una forma sencilla. Podríamos pensar en ello como una colección similar a un Dictionary<TKey,TValue> pero simplificada, en la que únicamente nos interesa la parte de la clave del mismo. Los HashSet<T> utilizan un algoritmo de hashing para indexar sus elementos, lo que supone varias implicaciones: por una parte, ocupa más espacio en memoria que otras colecciones pero, por otra, sus operaciones de búsqueda y borrado son extremadamente rápidas, de O(1). Asimismo, al realizar una inserción nos indica si el elemento ya existía previamente en la colección.
Modificando ligeramente el código y adaptándolo al filtrado de elementos con HashSet<T> quedaría:
public List<int> Filter(HashSet<int> allowedElements, List<int> elements)
{
var filteredElements = new List<int>();
foreach (var mElement in elements)
{
if (allowedElements.Contains(mElement)) filteredElements.Add(mElement);
}
return filteredElements;
}
Otro aspecto interesante acerca de los HashSet<T> es que implementan la interfaz ISet<T> y, por ello, nos ofrecen métodos relacionados con las operaciones que hemos comentado al inicio del artículo:
UnionWith(IEnumerable<T> other): realiza la operación aritmética de unión.ExceptWith(IEnumerable<T> other): realiza la operación aritmética de diferencia.IntersectWith(IEnumerable<T> other): realiza una operación de intersección.
Todas ellas son muy eficientes y se recomienda utilizarlas en ámbitos en los que premia un rendimiento. No confundir con los métodos de LINQ con nombre similar (Union(), Except(), Intersect()), puesto que su implementación es completamente diferente, así como su rendimiento, que es – generalmente – menor en LINQ. Aplicando estas operaciones al último ejemplo quedaría:
public IEnumerable<int> Filter(ISet<int> allowedElements, ISet<int> elements)
{
allowedElements.IntersectWith(elements);
return allowedElements;
}
En un set de pruebas con 100.000 elementos disponibles, de las cuales queremos hacer un filtrado eliminando 10.000 y manteniendo los 90.0000 restantes, hemos lanzado los tres métodos de filtrado expuestos y hemos obtenido los siguientes resultados:
- Contains con List<T>: 4300ms
- Contains con HashSet<T>: 7ms
- IntersectWith del ISet<T>: 3 ms
Como hemos explicado, HashSet<T> no es una colección que nos valga para solucionar todos los problemas y, en la mayoría de ocasiones, utilizar un List<T> será mejor y más sencillo. El uso HashSet<T> implica tener en cuenta sus principales características: sus elementos no están ordenados, no se pueden repetir, su inserción es ligeramente más lenta debido al cálculo del hash y ocupa más espacio en memoria que el List<T>.
Como conclusión, si necesitamos gestionar una colección muy grande de objetos de una manera muy rápida conviene evaluar el uso tanto el SortedSet<T>, en las ocasiones en las que sea importante que los elementos se encuentren ordenados, y HashSet<T> en el caso de que esto no sea así.
* Usar la expresión "más óptimo" es incorrecta, ya que el término óptimo significa "bueno en grado sumo" y por ello no admite marca de grado.