
Existen muchas y diversas estructuras de datos ya implementadas en los lenguajes de programación. Cada una de ellas tiene sus puntos fuertes y sus puntos débiles, por lo que se debe escoger con criterio cuál utilizar dependiendo de la situación.
Hoy voy a hablaros de una de ellas, el Dictionary. Para los que no lo sepáis un Dictionary es una implementación de un HashTable, pero con los tipos definidos. Es decir, a la hora de crearlo, debes establecer el tipo de los datos y de las claves que va a contener. En un HashTable no es necesario por lo que realiza continuamente boxing/unboxing de los objetos con lo que su rendimiento es inferior. En .NET se recomienda utilizar Dictionary frente a los HashTable por los puntos antes expuestos.
El Dictionary se caracteriza por utilizar pares "clave-valor". A la hora de añadirle un elemento tenemos que especificar una clave y el valor a guardar. Esa clave será la que le utilicemos cuando queramos recuperar el valor. Además un Dictionary no puede tener claves repetidas.
El Dictionary es una estructura de datos muy eficiente a la hora de buscar un elemento concreto. Voy a tratar de explicar a grandes rasgos cual es su funcionamiento, para que entendamos cómo consigue ser tan rápido.
Un Dictionary siempre parte de un número de posiciones iniciales que puede contener. Cada una de estas posiciones es conocida como un bucket. El número de buckets iniciales se puede establecer al instanciar el Dictionary. Si no se especifica se le asignará un número por defecto. El número de buckets siempre es un número primo (más adelante explicamos el motivo), por lo que si le establecemos un número que no sea primo él mismo se encargará de buscar el siguiente número primo mayor que el establecido.
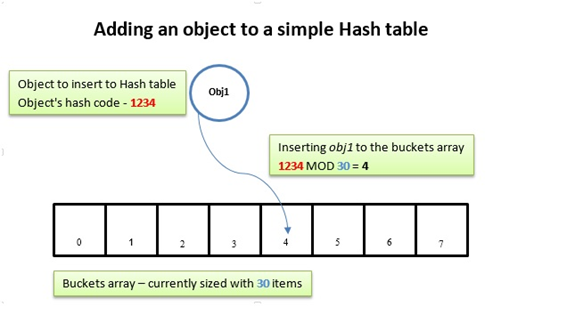
Por ejemplo, supongamos que instanciamos un Dictionary con 30 buckets.
Al añadir un nuevo elemento el funcionamiento es el siguiente:
- Se obtiene a partir de la clave un código Hash. Es decir, a partir de los bytes de la clave se genera otro conjunto de bytes, los cuales siempre serán los mismos para una misma clave. Si no se ha especificado el algoritmo de hashing al instanciar el Dictionary, éste utilizará por defecto
System.Object.GetHashCode. El valor devuelto por la función Hash debe ser un Integer. Como curiosidad comentar que cuando la función de Hash genera un número negativo se le aplica un AND con el mayor valor posible para un Integer:ValorHash AND Int32.MaxValue(2147483647 ó 0x7FFFFFFF), con lo que conseguimos volverlo positivo (obtenemos su valor absoluto). Un número negativo no es válido, ya que este número nos tiene que ayudar a buscar un bucket en concreto donde almacenar el valor... - Se divide el número obtenido mediante Hash entre el número de buckets (k) del Dictionary, y nos quedamos con el resto.
ValorHash MOD k. En este ejemplo:ValorHash MOD 30. - El número obtenido será la posición (bucket) donde almacenaremos el par "clave-valor". La operación MOD siempre devolverá un número entre 0 y k-1, en este caso entre 0 y 29, lo que viene perfecto para el index.
Al recuperar un elemento se realiza una operación similar:
- Se obtiene a partir de la clave un código Hash (un Integer)
- Obtenemos el MOD
- Buscamos en ese bucket el elemento.
De esta forma un Dictionary puede encontrar un elemento muy rápido, ya que no necesita recorrerse todos los elementos para encontrarlo.
Sólo hay un problema... ¿Qué pasa cuando el algoritmo de hash genera un mismo número para dos claves diferentes (lo cual es poco frecuente), ó cuando el módulo obtenido ya se había utilizado antes para otra inserción (más frecuente)?.
En estas dos situaciones el bucket donde debemos insertar el elemento ya se encuentra ocupado...
Este problema se llama "colisión" y para hacerle frente el Dictionary utiliza una solución llamada Separate Chaining.
La solución se basa en que cada bucket, en vez de un único elemento, contiene una lista de elementos. De esta forma, cuando se produce una colisión, en el mismo bucket tendremos más de un elemento.
La forma de implementar este mecanismo por parte del Dictionary es la siguiente:
- En un Dictionary siempre tenemos dos arrays, uno es el de los buckets, y el otro es el de los elementos. Ambos tienen el mismo número de posiciones.
- El array de los buckets contiene índices del array de elementos. Es decir, sus posiciones ocupadas "apuntan" a un elemento concreto del array de elementos.
- El array de elementos contiene la siguiente estructura en cada una de sus posiciones ocupadas:
- El valor del Hash
- La clave
- El valor
- Next: es un índice al siguiente elemento del listado referenciado por el bucket (-1 cuando es el último elemento de la lista)
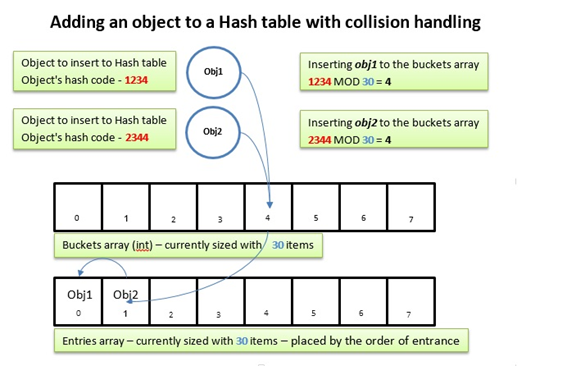
Por tanto el array de elementos puede contener sublistas dentro de él con sus elementos linkados por el valor de su atributo Next (similar a un LinkedList). De esta forma, a pesar de gestionar sólo dos arrays, cada uno de los buckets puede tener un listado de elementos propio.
Así que cuando buscamos un elemento en un Dictionary es posible que acabemos haciendo un recorrido por una lista hasta encontrar el valor deseado. El tamaño de estas listas suele ser bastante pequeño por lo que el tiempo requerido para recorrerla es muy corto.
El otro problema al que se enfrentan los HashTable (el Dictionary es una implementación de un HashTable) es la situación en la que quedan pocos buckets libres (LoadFactor). El LoadFactor es una estadística que determina el nivel de ocupación del Hashtable, y se calcula dividiendo el número de elementos (n) entre el de buckets (k). LoadFactor = n/k.
Cuando aumenta el LoadFactor el número de colisiones también lo hace. Un número que se suele utilizar habitualmente como LoadFactor máximo es 0.75. Al alcanzarse este número el HashTable debe crecer y aumentar su número de buckets disponibles. El problema es que para hacer eso se deben recalcular las posiciones de todos los elementos (hacer el hash y obtener el módulo), lo cual es lento, ya que es el equivalente a tener que volver a insertar todos los elementos. (No siempre se recalcula el hash, depende de la implementación del HashTable)
Para el Dictionary el valor máximo de LoadFactor es igual a 1. Esto es debido a que aumenta de tamaño en el momento en que queremos añadir un nuevo elemento y su array de elementos no tiene posiciones libres. En ese caso tenemos tantos elementos como buckets (n/k = 1). Eso no quiere decir que todos sus buckets estén ocupados, recordad las colisiones y el Separate Chaining...
Para aumentar el número de buckets lo que hace el Dictionary es multiplicar por dos el número actual de buckets y buscar el siguiente número primo que sea mayor. Posteriormente vuelve a realizar las operaciones de módulo para situar los elementos en sus buckets correspondientes. (El Dictionary sólo recalcula el hash bajo ciertas condiciones relacionadas con el número de colisiones)
/*Array con los números primos utilizados por Dictionary (si el número es mayor que 7199369 se hace internamente el cálculo del siguiente número primo)*/
public static readonly int[] primes = {3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919, 1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591, 17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437, 187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263, 1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369};
Al utilizar un número primo como número de buckets se reduce la posibilidad de colisiones, ya que un número primo sólo es divisible entre 1 y él mismo. Por ejemplo, si usáramos 100 cómo número de buckets, este es divisible entre 1, 2, 4, 10, 20, 25, 50 y 100. Cualquier número múltiplo de uno de ellos acabaría en un bucket también múltiplo de ese número, con lo que habría muchas colisiones en ciertos buckets concretos...
Si sabemos de antemano el número máximo de elementos que va a poder contener el Dictionary lo más correcto es establecerlo al instanciarlo, ya que así nos ahorramos todo el proceso de aumentarlo de tamaño.
Por último es relevante comentar que el Dictionary sólo aumenta de tamaño, nunca disminuye. Si en un momento dado tenemos millones de elementos y después de un borrado sólo unos cientos, el Dictionary seguirá teniendo millones de buckets... En ese caso probablemente sea mejor crear uno nuevo para recuperar la memoria reservada por la estructura.
A modo de conclusión: un Dictionary es una estructura de datos muy eficiente a la hora de recuperar un elemento determinado, pero su velocidad a la hora de insertar elementos y la mayor capacidad de memoria que necesita no lo hacen recomendable para ciertas situaciones. Si el número de elementos que va a contener no es muy grande es posible que el cálculo de los hashes haga que sea más eficiente una estructura con búsqueda lineal, cómo un array o un List<T>.
Otro aspecto a tener en cuenta es si el número de elementos que va a contener cambia con mucha frecuencia, ya que el proceso de aumentar su tamaño es muy costoso.
Esto no quiere decir que no haya que utilizar Dictionary, al contrario, es una estructura estupenda en muchas situaciones, pero no en todas...
Si queréis profundizar más en el tema os dejo unos links:
https://www.codeproject.com/Articles/500644/Understanding-Generic-Dictionary-in-depth
https://en.wikipedia.org/wiki/Hash_table
https://stackoverflow.com/questions/5379871/net-dictionary-impressively-fast-but-how-does-it-work